近距离图片识别并播报
这个项目可以识别任意图片,并通过语音播报出来。
这个项目的原理是:首先使用摄像头拍摄需要识别的图片组,然后将这张图片组传给模型进行训练。
这样再次遇到这张图片时,模型就可以识别出这张图片。最后将识别结果通过语音播报出来。
在此基础上加入超声波测距,只在近距离才调用摄像头,避免摄像头长时间工作发烫导致报废。
| 得分 |
|---|
| 通过 AI-Local 模型训练将摄像头识别到的不同的医疗垃圾进行标注(视觉识别素材由组委会提供),并将相应物品名称反馈在液晶显示屏上,目标物品置信度为 93%以上(高于 93%且分类正确得 5 分),非目标物品置信度为 85%以下(低于 85%得 5 分)。 |
| 语音合成技术完成不同物品的播报反馈,成功一类得 4 分(举例:此物为针头、是损伤性废物,应放入专用的针具容器中) |
| 识别到的物品名称和准确率反馈在显示屏上,不同物品的识别准确率在 90%以上。得 2 分。 |
| 程序分:初始化 camera 镜像、LCD 显示屏、音频播放器等,体现录入原始数据与训练数据的过程,存储模型路径、通信频率、概率阈值、模型学习框架选择均无误。得 2 分。 |
图片准备
我们以如下四张图片为例。将其逐一打印出来:
 |  |
|---|---|
 |  |
音频准备
设备不支持实施生成语音文件,因此在这里我们需要自己提前录制或合成好需要播报的音频。
可以使用在线工具或者软件来生成音频文件。譬如:https://products.aspose.app/audio/zh-cn/text-to-speech
合成好的音频按照物品名命名,放在 SD 卡根目录下,将 SD 卡插入设备。
例如你的物品名为zhi xing(直行的拼音),那么你的音频文件应该命名为zhi xing.wav。
下方代码中calss= ['zhi xing', 'yin hang', 'jin xing', 'mang dao']这行就表示了你的物品名分别为
zhi xing(直行的拼音)yin hang(银行的拼音)jin xing(禁行的拼音)mang dao(盲道的拼音)
物品名的命名仅供参考,要点是与音频文件的名称保持一致。
传感器连接
超声波T口:D0
超声波E口:D1
SD卡:SD卡槽
语音播报:拓展板自带
示例代码
由于 K210 内存不足,不一定能同时训练模型+加载模型,因此你可能需要分 2 次上传下面的代码:
- 第一次上传训练模型的代码,如果在出现 TRAIN OK 之后提示内存不足,不用担心,模型已经保存了。
假设我们训练四个物品:ABCD,每个训练5张
训练的流程为:先依次拍摄每个物品1张,再每个物品拍摄5张:
A B C D
A A A A A
B B B B B
C C C C C
D D D D D
- 第二次注释或删除这句代码:
ailocal.training(calss,5,"Cool_AI.ai")之后再次上传(下面的图形化代码应该已经注释了这句)
以下是完整代码
import sonar_no
import sensor
import player
import lcd
import board
import ailocal
#设定摄像头的参数,帧大小要大于224*224
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.run(1)
sensor.skip_frames(10)
#模型最佳图片大小为固定值:224*224 请勿更改
sensor.set_windowing((224,224))
#根据摄像头倒装与否选择是否开启垂直镜像
sensor.set_vflip(1)
#通信频率为固定值,背景颜色为16进制的RGB,可自选不影响程序
lcd.init(freq=15000000,color=0x0000)
#1.准备训练物品并录入名称 (理论数量不限,目前只支持英文名)
calss= ['zhi xing', 'yin hang', 'jin xing', 'mang dao']
#2.填写总的训练拍照数量(如四个物品,每个训练5张,总共20,并不同角度训练)
ailocal.training(calss,5,"Cool_AI.ai")
#3.保存模型下次直接模型加载,不需要再次训练模型
ailocal.loading("Cool_AI.ai")
#程序运行不停止
while True:
#如果超声波获取距离小于70厘米则执行下面程序
if sonar_no.Sonar(11, 12) <= 70:
#获取摄像头的图像
img = sensor.snapshot()
#4.运行模型,将返回识别到物品名list[0]及置信度list[1]
list = ailocal.predict(img,calss)
#将获取到的图像和判定结果绘制在屏幕上、删除不影响程序判定
print(list)
lcd.display(img)
#将获取到的图像和物品名list[0]及置信度list[1]绘制在屏幕上
lcd.draw_string(48,8,"{} {} %".format(list[0], list[1]),lcd.RED,0X0000)
#如果置信度大于80
if list[1] >= 80:
#播放物品名对应的音频
player.voice_en(1)
player.audio_play((("/sd/" + list[0]) + ".wav"),80)
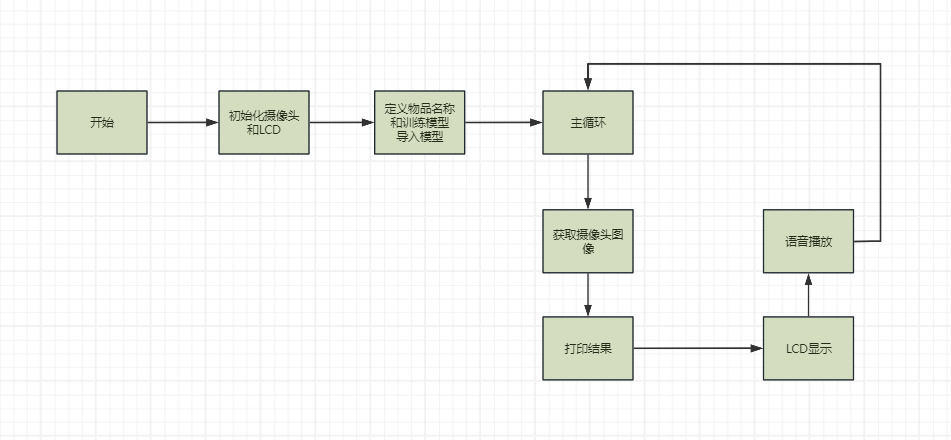
流程图